Blog
Agentic User Research
A preview of our AI Camp Berlin talk — notes from our user research pilot with Bolt, what Claude Code did well, and where the agent still lags a human expert.
The premise
We spent the last few months running a user research pilot with Bolt, built around a simple bet: if coding agents can already ship software, the same tools can do most of the busywork in a research project — and free researchers to do actual research. This is a short write-up of what we built, what worked, and where the agent is still behind a human expert — the same material we're presenting at AI Camp Berlin.
The basics
Before the flow, three bits of framing that matter.
What is an "agent"? A model running in a loop, using tools to achieve a goal. Agentic is a spectrum, not a binary — from a single prompt to systems that plan and act on their own.
Why Claude Code? Coding is where agents excelled first, so the tooling there is the state of the art. Claude Code happens to be a great general-purpose agent runner — think of it less as a "coding tool" and more as "Claude Agent". Claude Cowork is probably where this is heading, but isn't quite ready yet.
MCP and CLI, in non-tech terms. The CLI lets the agent run commands on your machine — read files, run scripts, open a browser. MCP (Model Context Protocol) is a shared "plug" format so any agent can reach into the apps you already use — Gmail, Drive, Figma, Linear, your own tools. Together they're how an agent actually reaches into your stack instead of just talking about it.
The podojo CLI. Our own CLI is how the agent reaches into the research platform itself — one command per step of the flow, from setting up projects and tests to pulling transcripts, assembling evidence reels, and shipping reports to stakeholders. Same surface a researcher would use, just driven by the agent.
The flow: from briefing to insight
The pilot followed a standard research project, but with Claude Code sitting next to the researcher at every step. Eight steps, one hub.
Agents absorb the busywork — researchers do the actual research.
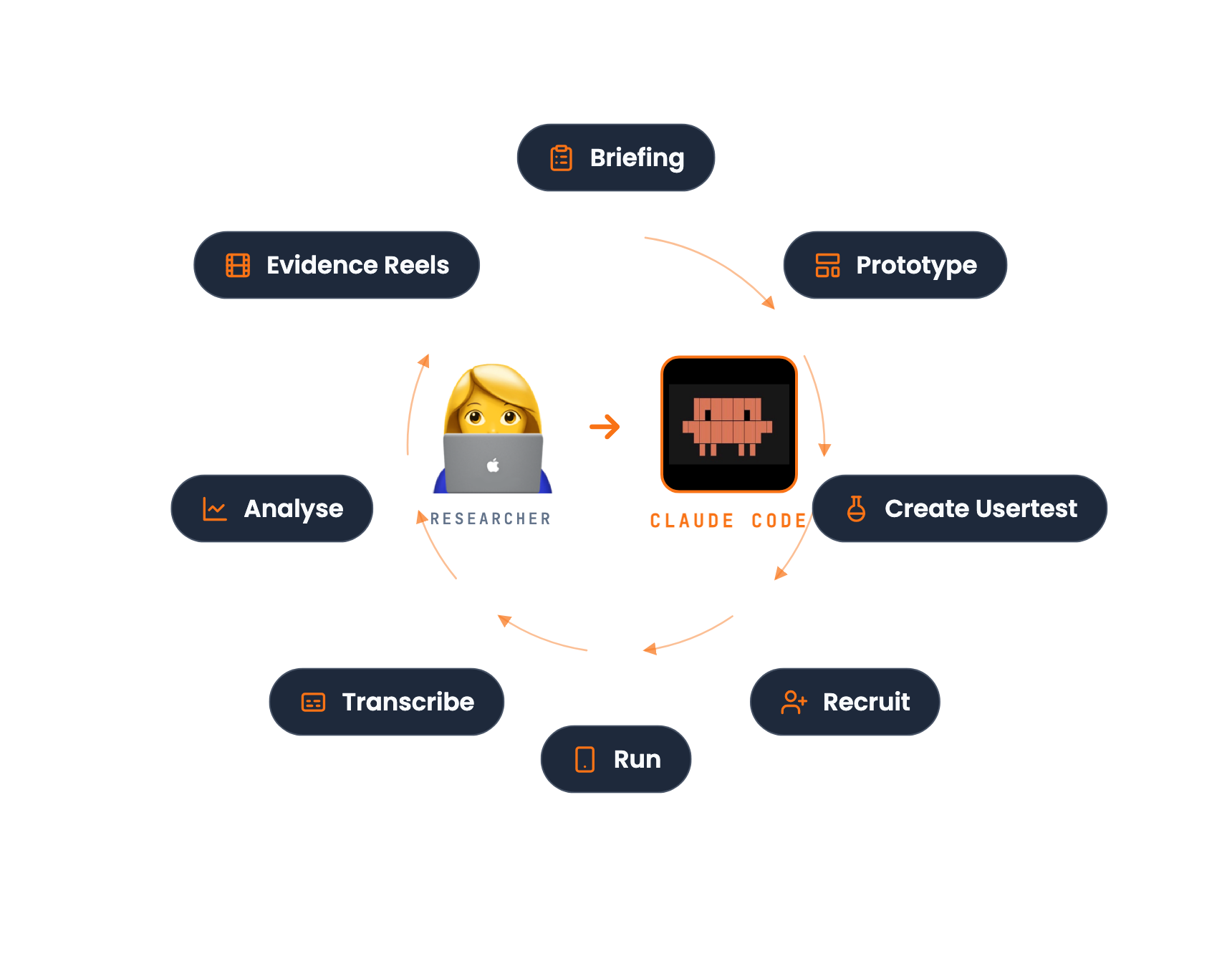
01 · Briefing
Align with stakeholders on what we're testing and why. We work through the research plan with Product, Design, and other stakeholders, and agree on the prototype concept — the hypothesis we want users to react to.
02 · Prototype
Code prototypes over mockups, every time. A working prototype gets better reactions than a clickable Figma, and an agent can produce one quickly.
Designers can now test their ideas in real code — before a single ticket is written.
- Figma Make — fast start, has weaknesses.
- Claude Code — the direction of travel for us.
- Figma MCP — not perfect, but helpful.
03 · Create Usertest
Most market tools force you through their own webapp — we needed something agentic, so we used podojo Usertesting. It runs in the browser on mobile (no app install) and the research brief flows straight into the test setup.
04 · Recruit
Bolt's research ops team built their own recruiting tool with our help. Large participant pool, easy to filter profiles and send invites. The key was making recruitment fit the rest of the flow, not bolting on a third-party panel.
05 · Run
Invite links go out via WhatsApp, SMS, or email. Tests are unmoderated, mobile-first, and about 15 minutes long. This is the one step where nothing new is happening on the agent side — it's just people doing the test.
06 · Transcribe
Videos are transcribed automatically, capturing audio, screen description, and on-screen interactions. This is the boring step that makes everything after it possible — a structured, searchable record of what actually happened.
07 · Analyse
This is where the researcher's time lands where it matters: interpretation.
- Filter — a skill flags unreliable participants and unusable feedback. Signal in, noise out, before analysis begins.
- Report — an agent-generated summary of findings: themes, quotes, ranked insights, recommendations.
08 · Evidence Reels
One reel per finding, auto-generated, with every claim linked to the exact clip it came from. That last bit is the important one: when a PM questions a finding, you click through to the moment. It collapses the "do I trust this?" loop from days to seconds.
How good are the results?
The fair question: is an agent-run report actually as good as a human researcher's?
We benchmarked it. Three steps:
- Baseline — a senior researcher's report on a set of interviews, locked in as ground truth.
- Agent run — the same raw interviews, processed end-to-end by the agent.
- Blind review — where expert and agent disagreed, a third researcher scored each finding.
The result:
- Agent alone — close, but below the expert. Not good enough on its own.
- Agent + showreel check — matches the fully manual report.
Agent + showreel check matches a senior researcher's report.
The showreel check is what closes the gap: because every claim links to a clip, a researcher can skim the reels and catch the handful of findings the agent got wrong in a fraction of the time it would take to re-analyse from scratch.
Caveat: this is a small dataset so far. Directional, not scientific.
What we're taking away
A few things we didn't expect going in:
- The agent's value isn't "doing research" — it's compressing the time between steps. Briefing to prototype, prototype to test, test to transcript, transcript to reel. Each handoff that used to take a day now takes an hour.
- Traceability beats accuracy. An agent that's 90% right and shows its work beats one that's 95% right and doesn't, because you can audit the first one in minutes.
- Researchers don't want to be replaced — they want the boring parts gone. Every researcher we've talked to wanted more time on interpretation, synthesis, and stakeholder conversations. This gives them that.